 |
IPSDK 4.2
IPSDK : Image Processing Software Development Kit
|
|
IPSDK 4.2
IPSDK : Image Processing Software Development Kit
|
| classesImg,clustersCentroids = | kernelKMeansImg (inImg,nbClusters,nbSamples) |
classifies pixels of an image using Kernel k-means algorithm
Kernel K-means algorithm consists in clustering a set of n points of d dimensions in k clusters.
This is an adaptation of the classical K-means which uses a radial basis kernel function to compute distances instead of the classical Euclidian distance.
This algorithm works in an augmented features space dimension to allow handling non linear clustering case such as follows :
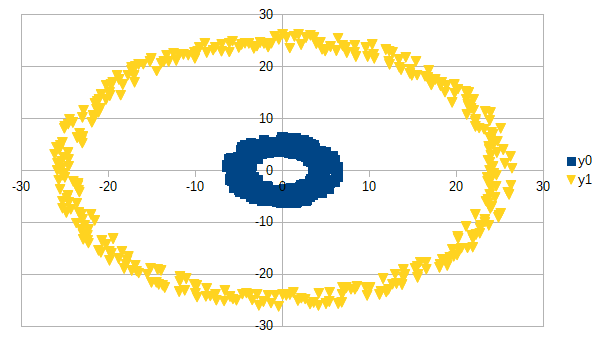
It also uses 'the kernel trick' to maintain reasonable feature space dimension and allows computation.
Applied here to image processing, for an input image 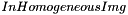 of size {x, y, z, c, t}, with c the number of color channels and t the number of elements in temporal sequence, it will clusters :
of size {x, y, z, c, t}, with c the number of color channels and t the number of elements in temporal sequence, it will clusters :
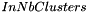 clusters.
clusters.For each attempt ( 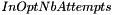 parameter) :
parameter) :
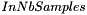 image values will be samples to random image coordinates. Each sample will then agregate images values along color and temporal plans and will be used as a features vector.
image values will be samples to random image coordinates. Each sample will then agregate images values along color and temporal plans and will be used as a features vector.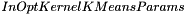 parameter.
parameter.Clustering result with the best separation value, which is defined by Dunn validity index (see ipsdk::math::clustering::eValidityIndexType), will be retained and stored into 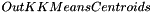 .
.
Finally, a clustering assignment using the 'best' clustering result on sample value will be computed on whole input image to generate 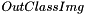 .
.
contains the parameters allowing automatic computation of radial basis kernel sigma value and accuracy threshold used during linear dependency analysis.Here is an example of Kernel K-means based classification :

